
Neuroscience should not blur the distinction between "forward" and "reverse" modeling
Part 2 of a series on neuroscience and the hyperreal

In the first post in this series, I outlined the case that neuroscience is on the verge of a hyperreal era, where models obscure the phenomena that they are models of. Two trends contribute to this phenomenon: the proliferation of models, and the growing scientific attention paid to models.
The concept of hyperreality comes from Jean Baudrillard’s 1981 book Simulacra and Simulation, a collection of impressionistic vignettes about how society has become enamored of models.1
Baudrillard was diagnosing a cultural syndrome that prioritizes representations — theories, models, pictures, movies, stories, artforms — over the things being represented. He seemed to be saying that a threshold has been crossed: representations are no longer used for their traditional purpose, which is to allow people to refer to things, processes, people, phenomena, and in doing so contend with those things. In a hyperreal condition, representations become ends in themselves, enrapturing society so completely that they replace the things they represent.
So Baudrillard is saying we are in an era of representations without referent. Maps without territories. I'll grant that this sounds a bit hyperbolic, but sometimes one has to exaggerate a description of something to draw attention to it.
I believe there is a great deal of ambiguity and equivocation surrounding models, despite — or perhaps because of — their ubiquity in science. So in this post and the next one, I’d like to lay out a couple of useful lenses for viewing scientific models.

Forward and Reverse Modeling
A scientific model is a representation of a natural phenomenon. The idea of creating analogues of phenomena has been around for thousands of years. Ancient architects and sculptors probably used small material models to plan out larger works. And until fairly recently, tangible models were a standard part of many scientists' toolkits. Francis Crick and James Watson, for example, used ball-and-stick models of molecules to uncover the structure of DNA. Nowadays, models are made of mathematical rather than physical parts, and since the math is typically too complicated to calculate by hand, they are also made of computational parts.

It's handy to think of two broad classes of mathematical modeling: "forward" modeling and "reverse" modeling. The systems biologist and mathematician Jeremy Gunawardena defines these two categories in his paper "Models in biology: ‘accurate descriptions of our pathetic thinking’":
Reverse modeling starts from experimental data and seeks potential causalities suggested by the correlations in the data, captured in the structure of a mathematical model. Forward modeling starts from known, or suspected, causalities, expressed in the form of a model, from which predictions are made about what to expect.
The Ptolemaic model of the solar system is a good example of a reverse model. Over the course of millennia, stargazers in the Fertile Crescent accumulated a "database" that astronomers of classical antiquity used to create an efficient system for predicting the positions of the sun, the moon, and the planets. The model was very accurate, but it was not framed as a consequence of underlying physical phenomena. For this reason, there was no real way to use the Ptolemaic model to say something about phenomena other than the solar system.
A Newtonian account of planetary motion is an example of forward modeling: it starts with the universal law of gravitation, using it to derive the specific trajectories of two or more celestial bodies. But the applications of Newtonian thinking are far more general than this: it can be used to model terrestrial motion, as well as the motion of artificial objects such as projectiles or satellites.
So a forward model moves from causal hypotheses (or scientific laws) to observations, whereas a reverse model moves from observations to causal hypotheses.
In neuroscience, the Hodgkin-Huxley model is an example of a forward model. It represents the mechanism of action potential generation in terms of well-established physical and chemical laws pertaining to electrical phenomena, adding crucial phenomenological “placeholders” to capture the distinctly biological aspects of the phenomenon. The model has been so successful at capturing the voltage dynamics of cellular membranes that it is sometimes treated as the ground truth.
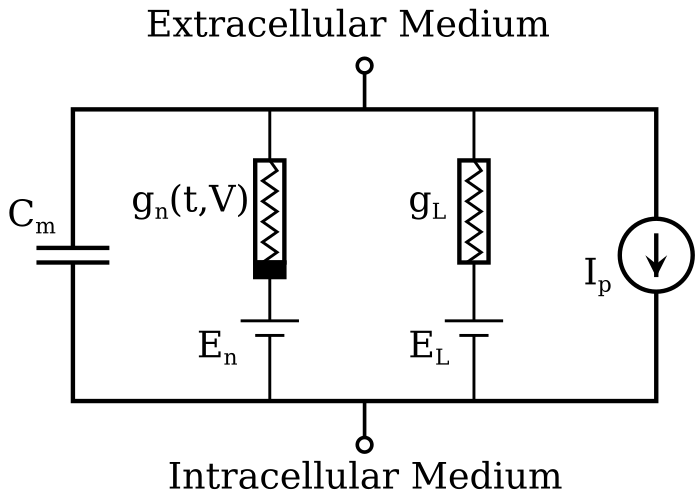
An example of a reverse model is the "Poisson neuron" model, which frames a stream of action potentials from a neuron as a series of random coin-flips. For many purposes, this is an adequate model: when cortical neurons are firing at a low rate, their activity does look a lot like a series of coin flips. If you start with the data — low-rate firing from cortical neurons — then the coin-flip model is the simplest way to capture the unpredictable nature of low-frequency spiking.
The coin-flip model of spiking is pretty much the bare minimum of a mathematical model: it posits a probabilistic phenomenon and nothing else. So it is purely descriptive, and doesn't really lead to causal hypotheses. Most reverse models do a little more, enabling researchers to find "statistically significant" differences in datasets. This kind of modeling is a mainstay of research in biology and psychology: it is how scientists decide whether there is a stable phenomenon in the first place.
For example, two groups of people who have different variants of a gene might be compared along some dimension, such as whether or not they have a psychiatric disorder. If the difference between the two groups crosses some threshold of significance, researchers tend to infer that the allele that is "associated" with the group that has the disorder might play a causal role in that condition.
As these examples suggest, many reverse models are also statistical models. In the previous post I mentioned the distinction between statistical and mechanistic models. Mechanistic models encode the mechanisms that the modeler thinks are instrumental in bringing the phenomenon about. So mechanistic modeling overlaps quite a bit with forward modeling.
Statistical models are mechanism-agnostic, seeking the simplest mathematical forms to characterize the data without mediation by physical and ostensibly "real" causes or tendencies. A good statistical model can help generate mechanistic hypotheses, which in principle can be used to create a forward model. In practice, however, this sort of feedback loop between forward and reverse modeling rarely happens.
One step forward, two steps back?
When I give talks2 about modeling, I often use the forward/reverse distinction, which I typically map onto the mechanistic/statistical distinction. But as I started putting this essay together, I realized that the alignment between these two distinctions is slipping. This is because artificial neural network (ANN) models, which are becoming more and more popular, are both reverse models and mechanistic models.
ANNs can be used to extract patterns from any sort of dataset. So in any field other than neuroscience, ANNs are unambiguously used as reverse models. But within neuroscience, it is tempting to view them as mechanistic, given that they embody highly abstracted versions of neural causality.
Earlier I suggested that a feedback loop between forward and reverse modeling might be a good thing, so perhaps a modeling framework that combines the two approaches is a good thing? A dialectical synthesis of the two? A tech-driven disruption of staid old patterns of thinking?
I doubt it. There are several reasons to avoid short-circuiting the separation between forward and reverse modeling in neuroscience. The general tendency with machine learning (ML) approaches is to make data the primary focus and demote mechanistic thinking to a secondary concern — if it is considered at all.
Neuroscientists who like to use ANNs as mechanistic models might respond with the idea that every model of a complex phenomenon involves simplifications. In any case, aren't simplifications the whole point of science? The fact that ANNs leave out certain empirical details might be a feature rather than a bug.3
I agree with the general argument — up to a point. Yes, all models need to simplify and abstract reality. But not all simplifications are the same. Some models simplify in a way that leaves open the possibility of progressively adding nuance and detail — they often provide pointers for how to do so4. Other models are structurally rigid, foreclosing this possibility. They typically compensate for a lack of flexibility with some combination of convenience and technical efficiency.5
Thanks to their widespread adoption by the tech industry, the software packages used to build ANNs are now as standardized and easy to use as Lego blocks. The word "pipeline" is often used by modelers in this context, conjuring up the invisible reliability of good plumbing systems.
Despite the fact that these software packages are typically free and open source, their effect on researchers bears a certain resemblance to that of the walled garden philosophy of many tech companies, most notably Apple: "Do things our way and you'll find that everything goes smoothly. But try to color outside the lines and you'll be sorry."
To a first approximation, the only mechanistic ideas embodied by ANNs are the ones that were already baked into their architectures back in the 1980s. Many mechanistic hypotheses are illegible from the perspective of ANNs and other data-centric approaches. Modelers have an incentive to avoid adding new mechanisms to ANNs beyond simple variations in connectivity, because such additions make it harder to avail of all the nice smooth pipelines.
So neuroscientists now have access to models that are powerful from a statistical point of view, but are not very mechanistically extensible. This might not seem like a bad trade-off, given that the field was already using black-box statistical models prior to the ML revolution of the 2010s.
But I don't think that convenience is adequate compensation for the rendering of certain scientific questions unaskable. Overreliance on non-extensible modeling may also contribute to the hyperreal proliferation of models, since a new model needs to be trained whenever a new experimental technique is invented, or even when data from an existing technique drift “out of distribution”6 . So in the next post I'll make the case that at least some computational neuroscientists should resist the siren call of reverse-yet-mechanistic chimeras and pay more attention to extensibility.
Notes
Baudrillard's thinking forms part of that loose and mutually inconsistent matrix of ideas known as postmodernism. Postmodernism is notoriously hard to pin down, but one common through-line is "skepticism of meta-narratives." These meta-narratives include religious pieties as well as the Enlightenment values of rationality and scientific progress. Baudrillard’s notion of hyperreality might be thought of as a proliferation of micro-narratives, i.e., models without referent.
There is a certain irony in the claim that a scientific discipline can wind up in a hyperreal state. Isn't science opposed to the relativism and nihilism that many people accuse postmodernists of? There are many ways to respond to this line of thinking, but for now let's just say that any simple opposition between scientific and postmodern thinking misunderestimates the diversity of both.
Here’s a talk I gave on one of my models that starts with the forward/reverse distinction.
How the amygdala can act as an "emotional gatekeeper": a computational perspective
When computational neuroscientists are feeling circumspect and philosophical, they whip out two references: (i) statistician George Box’s aphorism “All models are wrong”, and (ii) Argentine writer Jorge Luis Borges’ clever little story “On Exactitude in Science”, which conjures up the image of an absurd empire that creates a map that is coterminous with the empire itself, and therefore “perfectly” accurate. I myself have used both of these in introductory lectures on computational modeling. But in recent months I have started to worry that this gesture towards epistemic humility can be used to preemptively ward off criticism. All models may well be wrong, but they are not all equally wrong, especially once you have chosen some criterion for rightness. So much fog arises from modeling that does not state its scope and goals explicitly.
The Hodgkin-Huxley model is a great example. It is not just a model of action potential generation in the squid axon: it is a framework that can be, and has been, extended. For example, calcium channels, which were not covered by the initial model, can be incorporated using the same basic approach. Even the Izhikevich model, which is highly simplified compared to the HH model, allows for extensions: I have been able to supplement it with HH-style calcium and KCNQ channels.
This may be an example of a family of trade-offs that include the efficiency-robustness trade-off and the stability-plasticity dilemma. I like framing decision problems in terms of trade-offs rather than optimal solutions, since trade-offs carry the implication that context and timing matter, and that a globally optimal solution may not be relevant or even computable given the constraints of the situation. Also, in a social group, such as a group of researchers, it makes sense to diversify strategies: some members should maintain stability and efficiency while others cultivate flexibility and robustness.
The very fact that the term “out of distribution” is used in ANN research indicates the proximity of ANNs to traditional statistical modeling, despite the presence of quasi-mechanistic elements. Both statistical and ML approaches rely on something akin to statistical stationarity: they are most reliable when used on test sets that come from the same distribution as the training sets. Newton’s laws, by contrast, can easily be extended outside their domain of prior historical usage. A recent paper that tried — and failed — to use ANNs to re-derive Newton’s laws vividly illustrated this contrast: “We particularly find that foundation models trained on orbital trajectories consistently fail to apply Newtonian mechanics when adapted to new physics tasks.”